
Machine learning 의 error는 2가지 source 가 있다.
- 열심히 하려했는데 , 설명이 잘 안된것. 즉 Approimation 이 망한것.
- 앞으로 올 데이터셋(testing)에 대한 오차.
f : true function
g : Maching learning Model ( Approximation)
g(D) : 주어진 데이터를 이용해 learning 된 function 들. Parameter inference 까지 된 Machine learing model.
D : 데이터셋
g(hat) : 현실의 모든데이터에 대해서 일부를 관측해서 ML을 만드는 과정을 반복한다고 할때, 계속 sampling 될때마다 거기에 맞는 g(D) 를 만들수 있다. 이것을 무한개를 만들어 평균을 내는것이다.

여기서 아래 우항의 Ed[Ex(~~)]=Ex[Ed(~~)]로 switch가 가능하다. 왜냐면 mean 값을 구하는 것이기 때문이다.
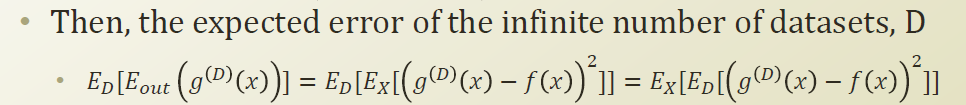
아래식의 빨간색 부분이 g(hat) 이기 때문에 전체적인 식이 0 이 될수 있다.
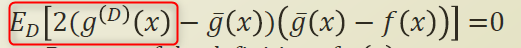

g(hat) :세상의 모든 데이터를 다봤다고 가정.
gD(x) : 우리가 가진 데이터넷은 결국 하나이다. 그것으로 만들어진 ML 모델.
Bias : 모델의 한계점에 의해 생길수 있는 에러.
True function 에 가까이 가기위해 모델을 complex 하게 만들어 bias를 줄일수 있지만 , 다양한 데이터에 의해 만들어질수 있는 hypothesis 와는 거리가 생긴다. 즉 Variance가 커진다.
'머신러닝 > 문일철 교수님 강의 정리 (인공지능및기계학습개론)' 카테고리의 다른 글
| Weeek 6.4 Cross Validation (0) | 2019.08.17 |
|---|---|
| Week 6.3 Occam's Razor (0) | 2019.08.17 |
| Week 6.1. Over-fitting and Under-fitting (0) | 2019.08.09 |
| Week 5.9. SVM with Kernel (0) | 2019.08.07 |
| Week 5.8. Kernel (0) | 2019.08.06 |
