Training and Testing

머신러닝의 아킬레스건 : 주어진 데이터셋의 분포가 변하지 않는다고 가정한다. 분포가 변하면 새롭게 training 해야한다.
우리가 가진 전체 dataset을 일부는 parameter inference 하는 Training에 쓰고 나머지는 testing 에 쓰인다. 얼마만큼 잘 작동하는지 확인하기위해..
DB가 만약 distortion 되어 있으면, testing 했을때 좋은 결과가 안나올수도 있다.
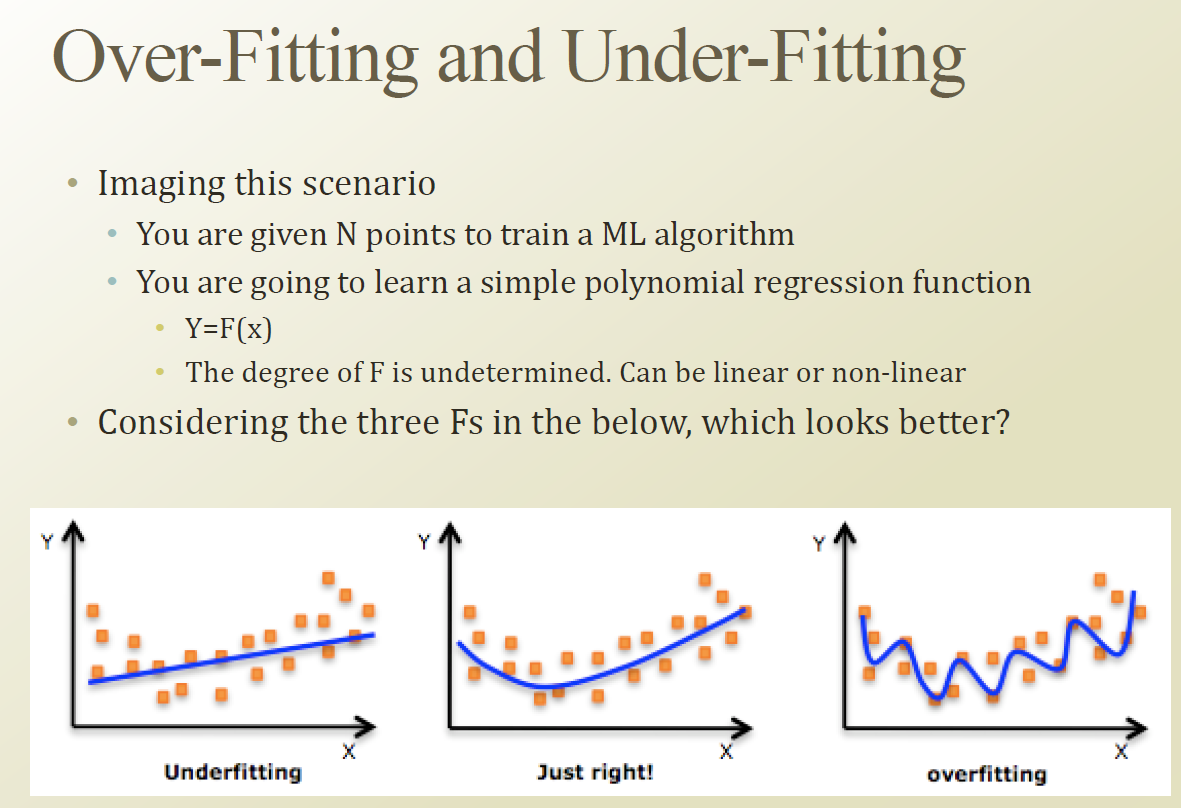
underfitting : 밥이 설익었다라 표현할수 있다.
overfitting : 밥이 너무 질었다라고 표현할수 있다. fitting 노력을 너무 많이 했고, 앞으로 올 데이터에 대해서 에러가 더 클수 있다.
underfitting / overfitting 을 어떻게 피할수 있을까? 이것을 Week6에서 배워야 할 학습 목표이다.
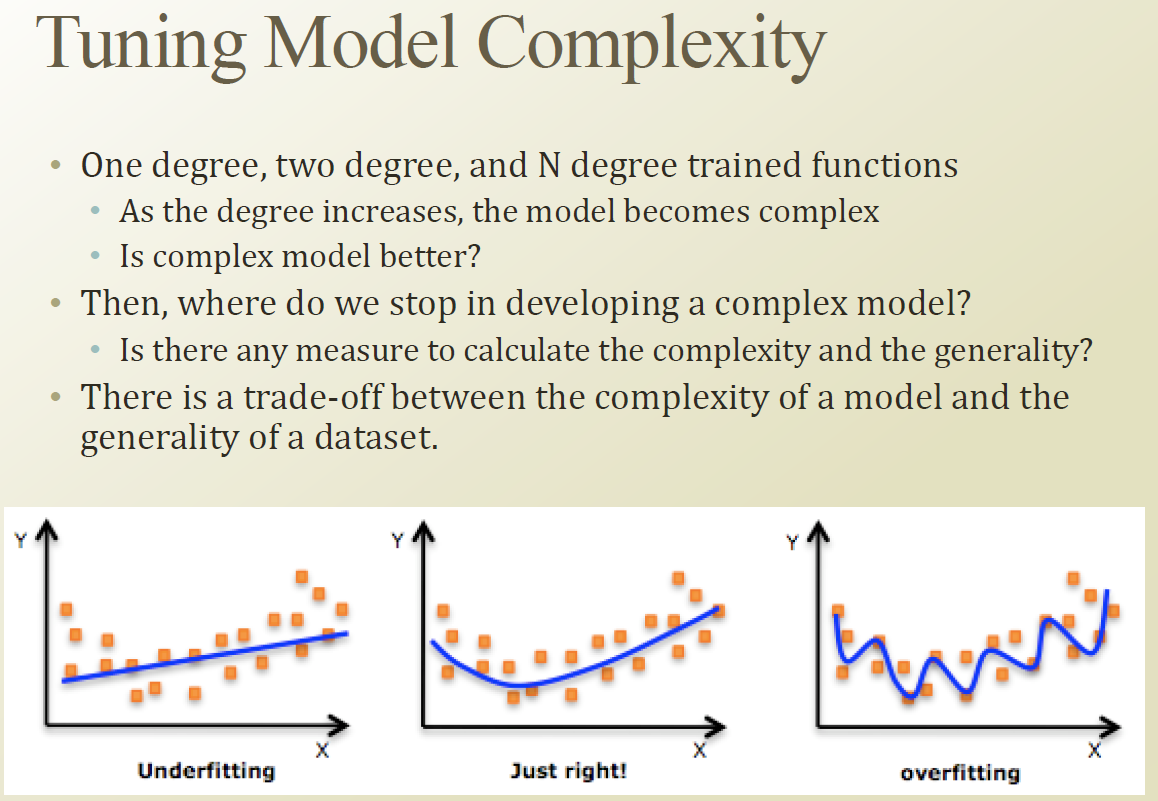
Complexity 와 Generality 사이에 trade off 관계가 있는데 이것을 정량화된 표현을 할수 있다. 그것은 다음시간에..
'머신러닝 > 문일철 교수님 강의 정리 (인공지능및기계학습개론)' 카테고리의 다른 글
| Week 6.3 Occam's Razor (0) | 2019.08.17 |
|---|---|
| Week 6.2. Bias and Variance (0) | 2019.08.10 |
| Week 5.9. SVM with Kernel (0) | 2019.08.07 |
| Week 5.8. Kernel (0) | 2019.08.06 |
| Week 5.7. Primal and Dual with KKT Condition (0) | 2019.07.20 |
