Forward Backward Probability를 좀 알아야 HMM 을 할수 있다. 그래서 Forward Backward Probability에 대해 알아보자.
HMM에서 다음과 같은 질문이 있을수 있다.
1. Evaluation question.

- π, a, b 가 알려저 있을고 , HMM의 구조를 가지고 X가 generate 되었다고 가정했을떄 얼마나 likely한 observation인지 evaluation 하는것.
π : initial state. latent state를 정의할때 쓰이는 parameter.
a : transtion 할때 현재 state에서 다음 state 이동할때 확률
b : 어떤 특정 state 에서 observation 이 generate 되어 나올 확률
X : 우리가 가진 관측값
2. Decoding question
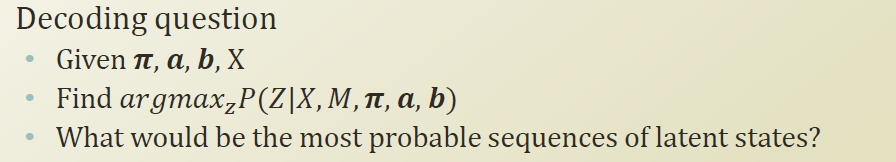
데이터셋을 알고(X), HMM의 구조이고 (M), π, a, b 를 알고 있을 때 , 가장 likely 한 latent factor 들의 sequece를 찾아내 봐라는 것이다.
다시말하면 데이터포인트와 latent factor는 다른것이다. 그러면 보이는 데이터 포인트를 가장 잘 설명할수 있는 latent factor들의 흐름을 알아내 보아라는것.
3. Learning question

X만 given 이고 (parameter를 모른다.) 주어진 데이터가 보일확률을 가장 maximize 해주는 π, a, b 를 찾아보는것.
즉 parameter를 learning 해봐라는것.

π, a, b 를 training dataset 이 있을 경우에 어떻게 알아볼수 있을까?
카지노에서 두가지 종류의 주사위가 있다고 하자. 하나는 Loaded dice라고 무게중심이 한쪽으로 쏠려 특정숫자가 나올확률이 높은 주사위 이고, 또다른 하나는 Fair dice로 일반 주사위이다.
딜러는 한번씩 Fair dice 대신 Loaded dice를 사용한다. 손님들은 주사위의 결과만 알수 있고, 딜러는 어떠한 주사위를 사용했는지도 안다.
여기서 주사의 던진 결과값은 관측값이고, 어떠한 주사위를 사용했는지는 latent factor가 된다.
딜러한테 어떠한 주사위를 사용했고, 그때 나온숫자를 기록해달라고 하여 아래와 같이 training dataset을 받았다고 하자. 이것을 supervised learnig 에 적용을해보자.

어떠한 주사위를 선택하는지에 대한 확률을 구해볼수 있다.
현재는 L이 었는데 다음에도 L일 확률을 계산할수 있다. => P(L=>L)
현재는 L이 었는데 다음에는 F일 확률도 계산할수 있다. => P(L=>F)
P(L=>L) 은 P( Zt+1= L | Zt = L ) 로 나타낼수 있고 이것은 parameter a 와 같다.
또한 관측된 숫자와 연결해 볼 수도 있다.
현재 L을 사용한 상태에서 주사위가 1이 나올확류을 계산할수 있다. => P( Xt = 1 | Zt = L )
즉 X 와 M이 주어진 상황에서 π, a, b 는 Counting을 통해 구할수 있다.

X,Z를 안다고 해보자. 그리고 Bayesian network라 가정해보면 Full joint probability를 알면 계산이 쉬워진다. (π는parameter라 생략한다.)
Loaded dice 가 1,2,3,4,5 가 나올 확률은 1/10 이라 가정하고 , 6이 나올확률은 5/10 라 생각해보자.
Loaded dice를 쓰면 70%의 확률로 다음에 Loaded dice를 쓴다고 가정해보자.
위의 가정에 대한 Evaluaton question에 대해 답을해보자.
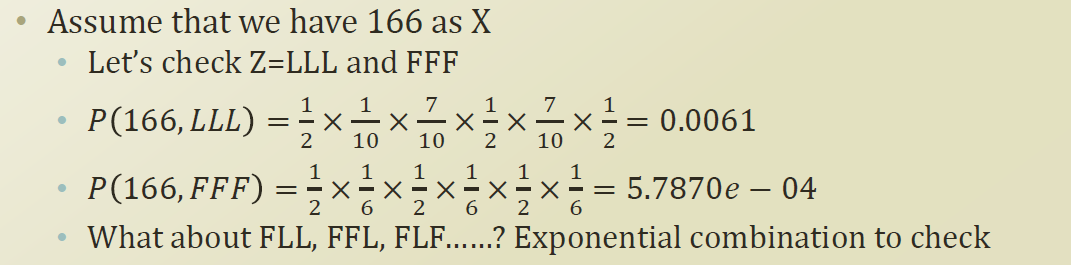
처음 1/2은 parameter π 라 생각하면 된다. (Loaded를 쓸지 Fair를 쓸지의 확률 : 여기서는 50%로 가정)
계산된 확률값을 통해 즉 여기서 Loaded dice를 3번 사용한것이 Fair dice를 3번 사용한것보다 좀더 likely 한 답이된다.
위의 2가지 시나리오뿐 아니라 총 8개의 시나리오가 가능하다. 하지만 다 check 하면 계산하기 어렵다. (decoding 하기가 어렵다는의미)
즉 다시 말하면 evaluation 하기는 좋지만 decoding 하기는 어렵다. decoding은 다른 방법을 써야한다.
그럼 decoding question을 어떻게 구할수 있을까?

우리가 실제 알수 있는것은 X 이고 Z는 모른다. GMM에서는 Z는 marginalize out 시켰다. 그래서 Z는 marginalize out 하고싶어진다. HMM 도 가능하다.

이것은 여러번 반복되어 계산해야한다. 그러면 이것을 좀더 단순하게 계산할 수 있지 않을까?
P(A,B,C)=P(A)P(B|A)P(C|A,B) 의 원리를 통해 단순하게 해보자.
x1~xt 까지는 데이터를 다 가지고 있고, ztk에 대해서만 모델을 추가했다고 해보자.
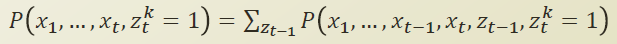
zt-1을 introduce 해서, zt-1에 대해 marginalize out 을 하면 , 기존식 𝑃(𝑥1,…,𝑥𝑡,𝑧𝑡𝑘=1)과 동일하다.
P(A,B,C)=P(A)P(B|A)P(C|A,B) 을 이용해 위 [식1]을 정리해보면 아래와 같이 표현된다.
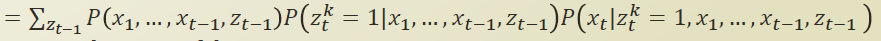
위 [식2]중 가운데 항을 한번 살펴보자.

위의 식에서 zt-1 이 알려저 있으면 bayes ball 에 의해서 앞부분은 몰라도 되기 때문에 , x1, ...., xt-1 부분이 없어진다.
그러면서 위의 식은 아래와 같이 표현 될수 있다.

또한 아래식도 zt를 알게되면 간단히 정리할수 있다.

이것도 bayse ball 에 의해 아래와 같이 정리된다.

그러면 위[식2]을 다시 정리해보면 아래와 같이된다.

[식3]의 Σzt-1 과 독립적이 항에 대해서는 아래와 같이 밖으로 뺄수 있다.

여기서 [식4]의 앞쪽 부분인

이것은 emision probability 인 b 의 parameter 로 쓸수 있다.
그리고 [식4]의 뒤쪽 부분인

이것은 transition probability인 a 로 나타낼수 있다.
최종적으로 식을 정리하면 아래와 같다.

여기서 𝑃(𝑥1,…,𝑥𝑡−1,𝑧𝑡−1) 부분은 우리가 처음에 구하려고 했던 𝑃(𝑥1,…,𝑥𝑡,𝑧𝑡𝑘=1) 의 reduced 부분이 된다.
즉 위의 반복되는 구조를 발견하였고 이것은 recursion(재귀) 이 된다. 즉 joint 인 𝑃(𝑥1,…,𝑥𝑡,𝑧𝑡𝑘=1) 이것을 α 로 표현하고 아래와 같이 쓸수있다.
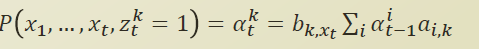
또한 아래 α 의 의미는 t번째 것이 k번째 클러스터에 있다. K번째 latent factor를 가진다는 의미이다.

'머신러닝 > 문일철 교수님 강의 정리 (인공지능및기계학습개론)' 카테고리의 다른 글
| Week 9.4 Viterbi Decoding Algorithm (0) | 2019.11.04 |
|---|---|
| Week 9.3 Forward-Backward probability Calculation (0) | 2019.10.17 |
| Week 9.1 Concept of Hidden Markov Model (0) | 2019.10.15 |
| Week 8.9 Derivation of EM Algorithm (0) | 2019.10.11 |
| Week 8.8 Fundamentals of the EM Algorithm (0) | 2019.10.10 |
