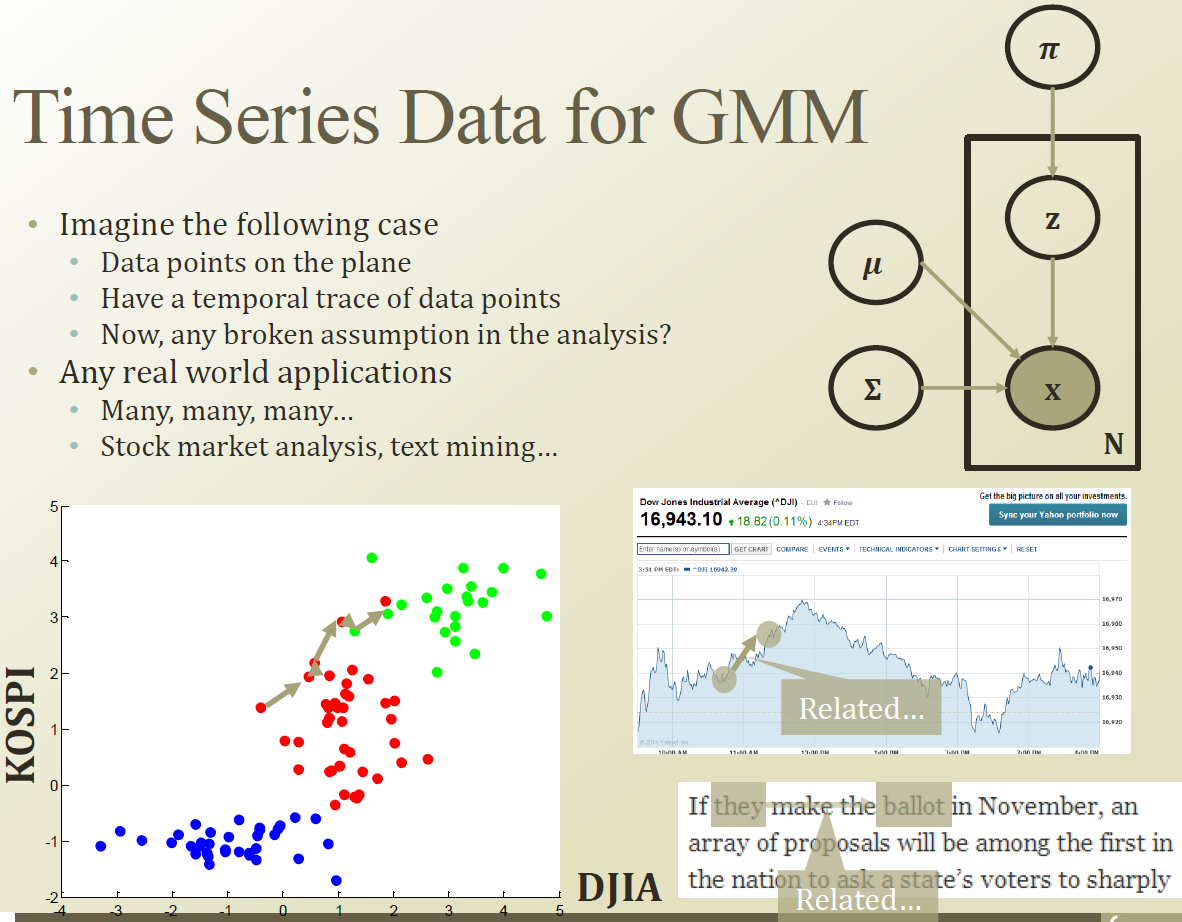
군집을 이루고 있다가 , time에 따라 point가 흘러간다고 생각해보자. 그러면 기존의 GMM 이 어떻게 바뀌어야 되는지에 대해 생각해보자.
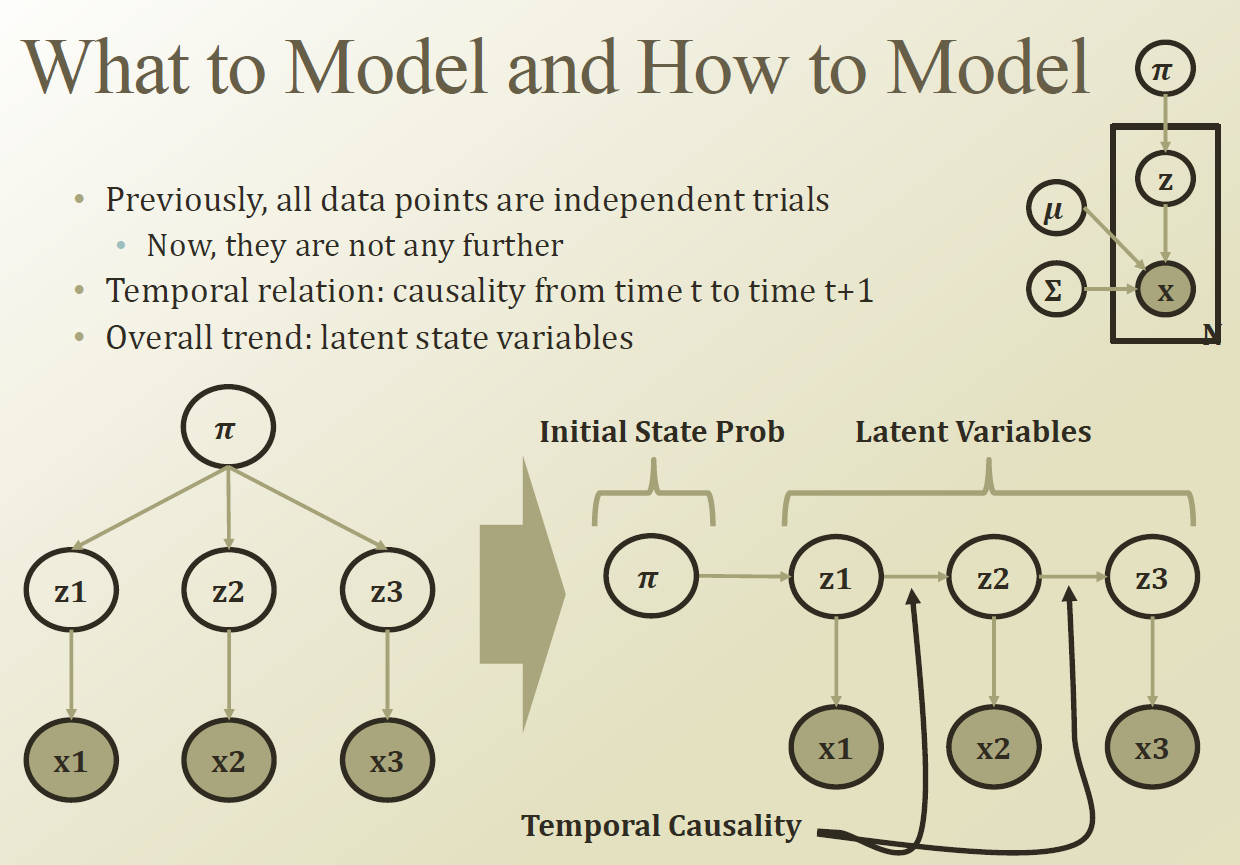
N : N개의 데이터 포인트
Z : latent factor ( 어떤 cluster 에 포함하는지 지정하는 factor)
Σ,π,μ : Parameter
π : Multinomial random variable
시간의 흐름에 따른 Latent factor(z1,z2,z3....)의 변화를 모델링.
x1 , x2 , x3 ...등은 관측된 값.
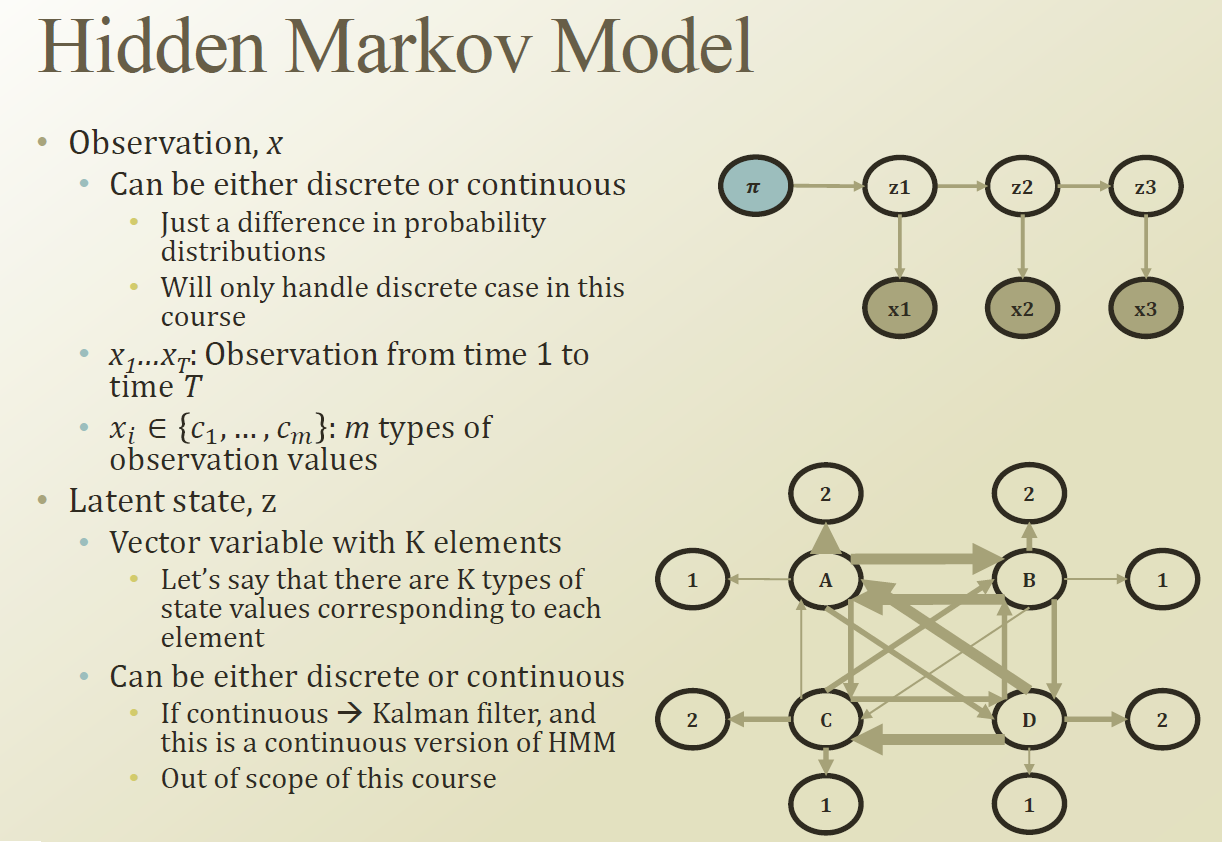
z1 과 x1 의 causality를 표현하는 방법 : P(X1|Z1)
k개의 군집이 있다고 해보자. K개의 component가 있다는 의미이다.
Latent factor가 continuous 하면 Kalman filter라 한다.

Initial state probabilityies
- Multinomial distribution 에서 sampling을 하는데 π 라는 parameter를 learning을 해야겠다
Transition probabilies (위 그림 2)
- 이전 time에 특정 클러스터에 있었는데 , 다음 time에는 어떤 클러스터에 있을까를 나타낸다.
- Multinomial distribution 으로 정의를 할수 있다.
- parameter a 를 사용한다.
- aij : i번째 클러스터에서 j번째 클러스터로 갈 확률.
Emission probabilities (위 그림 3)
- i 번째 클러스터에 있는데 그때의 x 값 (이번 강의는 discrete 한 경우만 다룬다.)
- parameter b를 사용
- bij : i 번째 클러스터에 있을때 , j 번째 observation을 찾아볼 확률

A,B,C,D : Latent factor 라 생각해보자. 다른 state로 확률로 천이될수 있다. 개별 state 에서 1 ,2 를 표현할수 있다.
예를 들어본다면 아래와 같다.
우리교수는 항상 화가 나 있다고 해보자.화가난 모습을 보는것은 observation 이다.
상태(latent factor)는 계속 변하고 있는데 , 상태에서 나온 observation은 항상 constant 하다.
혹은 교수의 표정은 항상 변하는데 (observation) 하지만 latent factor는 constant 할수도 있다.
시간에 따라서 Latent factor 에서 표출되는 observation 이 구분된다. 이것이 HMM의 특징이다.
'머신러닝 > 문일철 교수님 강의 정리 (인공지능및기계학습개론)' 카테고리의 다른 글
| Week 9.3 Forward-Backward probability Calculation (0) | 2019.10.17 |
|---|---|
| Week 9.2 Joint and Marginal Probability of HMM (0) | 2019.10.16 |
| Week 8.9 Derivation of EM Algorithm (0) | 2019.10.11 |
| Week 8.8 Fundamentals of the EM Algorithm (0) | 2019.10.10 |
| Week 8.7 Relation between K-means and GMM (0) | 2019.10.09 |
