이번 주차에서는 Support Vector machine 에 대해 배워본다.
예전 강의에서 배웠던 Decision Boundary에 대하여 다시 한번 살펴보자.
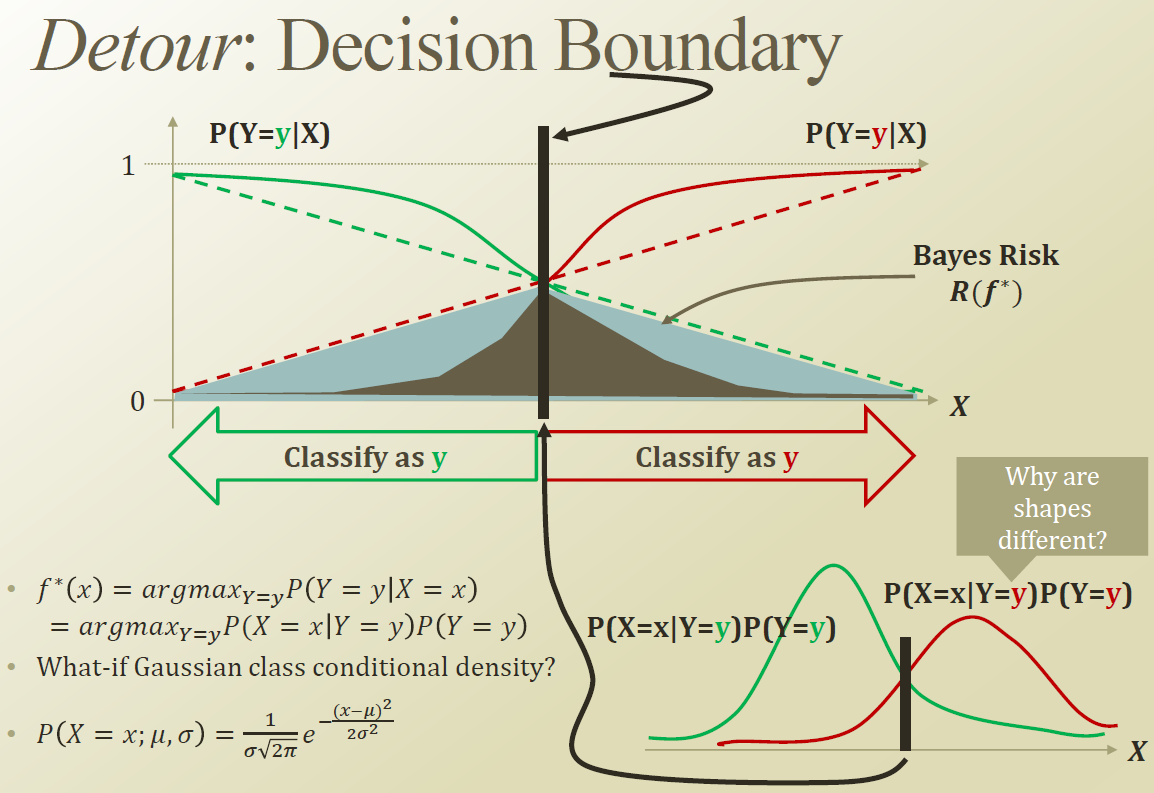
Logistic Regeression 에서 S- Curve / Sigmoid 함수를 쓰는이유가 Decision boundary 근처에서 급격한 Posterior 분포의 변화를 관측할수 있기때문이다.
Decision Boundary가 어떻게 구성되냐에 따라 Learning 의 성능이 결정될수 있다.

평면상에 점들을 흩어 넣고 Decision Boundary를 정해보라고 하면 어떻게 할수 있을까? 위의 그림을 보았을때는 빨간색 점들과 파란색 점들 사이에 선을 긋게되면 잘 분류되었다고 할수 있다.
그러면 그 중에서도 가장 나은 선택을 해야하는데 어떤 DB line이 가장 좋은 선택이 될수 있을까?
각각의 점과 DB line이 멀수록 좋은 선택이 될수 있다.

위의 그림에서 빨간색 두점을 잇는 빨간선을 긋고 , 그 기울기를 유지한체 쭉쭉 내려오면서 가장 먼저 만나는 파란색점을 통과하는 선을 그어보자.
이 두개의 평행한 선 사이에 가운데 선을 그어보자.(연두색 선) 이선이 이 그림에서 그릴수 있는 최적의 DB Line이 된다.
여기서 핵심은 위 그림의 빨간 2점과 파란 1점 , 즉 3개의 점을 찾아내는것이 핵심이다.
즉 Support vector machine은 DB를 support하는 몇개의 vetor를 찾아내는것이 핵심이다.
필요한 parmeter는 x1, x2, b 의 3개가 필요하게된다.
위의 그림에서 빨간색 점들은 Positive case 라 생각하고 , 파란색점들은 Negative case 라 생각해보자.
DB 를 Wx+b =0 이라 하고 , 빨간색 점들은 Wx+b >0 이 되고 파란색점들은 Wx+b <0 가 되게 된다.
Positive는 +1 , Negative를 -1로 모델링하게 되면 Confidence level은 항상 양수가 된다.
우리의 목적은 Confidence level를 최대한 높여주는것이다.
'머신러닝 > 문일철 교수님 강의 정리 (인공지능및기계학습개론)' 카테고리의 다른 글
| Week 5.4. Error Handling in SVM : 서포트벡터 머신에서의 오류처리 (0) | 2019.07.19 |
|---|---|
| Week 5.2. Maximizing the Margin (0) | 2019.07.18 |
| Week 4.8 Naive Bayes vs Logistic Regression (0) | 2019.07.17 |
| Week 4.7. Naive Bayes to Logistic Regression (0) | 2019.07.08 |
| Week 4.6. Logistic Regression Parameter Approximation 2 (0) | 2019.07.02 |
